
¿Qué es el Edge Computing?





El Edge Computing es una de las tecnologías que definirá y revolucionará la manera en la que humanos y dispositivos se conectan a internet. Afectará a industrias y sectores como la del coche conectado, los videojuegos, la Industria 4.0, la inteligencia artificial o el machine learning. Conseguirá que otras tecnologías como la nube o el internet de las cosas sean aún mejores de lo que son ahora.
Para entender bien qué es el Edge Computing es necesario comprender antes cómo funcionan algunas tecnologías como la nube (también conocida como cloud computing). ¿Qué es lo que ocurre cada vez que nuestro PC, nuestro smartphone o un dispositivo cualquiera se conecta a internet para almacenar o recuperar información de un centro de datos remoto?
Qué es el Cloud Computing
La nube está tan presente en nuestras vidas que lo más probable es que la utilices sin darte cuenta. Cada vez que subes un archivo a un servicio como Dropbox, que consultas tu cuenta en la aplicación del banco, cada vez que accedes a tu correo o incluso cada vez que utilizas tu red social favorita estás haciendo uso de la nube. Simplificándolo mucho, podemos decir que utilizar la nube consiste en interaccionar con datos que se encuentran en un servidor remoto y al que accedemos gracias a internet.
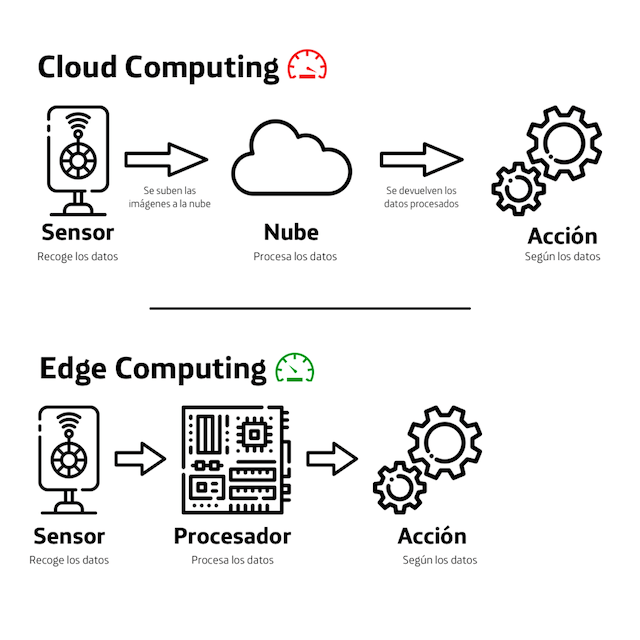
Cuando lo hacemos, el procedimiento es más o menos el siguiente: tu dispositivo se conecta a internet, ya sea a través de red fija o de red inalámbrica. Desde ahí, tu proveedor de internet, generalmente una operadora como Telefónica, se encarga de llevar los datos desde tu dispositivo hasta el servidor de destino, utilizando una dirección IP o una dirección web (por ejemplo dropbox.com o gmail.com), para identificar el sitio al que se debe enviar la información.
El viaje de los datos hasta que se procesan en la nube
El servidor en cuestión procesa tus datos (procesar es un término clave aquí, como vamos a ver), opera con la información y devuelve una respuesta. Por ejemplo: cuando te conectas a Gmail a través de tu dispositivo, pides al servidor de Google que te muestre el estado actual de tu bandeja de entrada, este procesa tu solicitud, consulta si tienes correo nuevo y te devuelve la respuesta que ves en tu pantalla. Como los datos están en la nube, da igual el dispositivo desde el que lo hagas.
Aunque parece simple, este “viaje” de la información es una maravilla de la tecnología que requiere toda una serie de protocolos y elementos dispuestos en el lugar correcto. Sin embargo, tiene también algunas desventajas. Pongamos por ejemplo que tú vives en España y el servidor de la nube en cuestión se encuentra en San Francisco. Cada vez que te conectas tus datos tienen que hacer el viaje de ida a través de la red de tu proveedor de acceso a Internet y de otros operadores esperar al procesamiento de datos en el procesador (o procesadores) del destino y luego hacer el camino de vuelta.
Además de que no es habitual que los servidores estén tan lejos, para muchas de las cosas en las que utilizamos el cloud hoy en día esto es totalmente normal y válido, los tiempos son tan bajos (hablamos de milisegundos) que no nos damos ni cuenta. El problema llega en determinados casos de uso donde cada milisegundo que pasa es crucial y necesitamos que la latencia y el tiempo de respuesta del servidor, sea lo más bajo posible. Algunos de esos escenarios de uso frecuentes tienen que ver con el Internet de las Cosas.
Por qué es importante el IoT
El Internet de las Cosas, o IoT, es el sistema que conforman miles y miles de dispositivos, máquinas y objetos interconectados entre sí y a internet. Con tal cantidad, es lógico asumir que tanto el volumen de datos generado por cada uno de ellos como el número de conexiones a los servidores se dispare exponencialmente.

Algunos de los objetos que hoy en día ya se conectan con asiduidad al internet de las cosas son por ejemplo bombillas, termostatos, sensores industriales en fábricas para controlar la producción, enchufes inteligentes, altavoces virtuales con asistentes de voz como Movistar Home, Alexa y Google Home o incluso coches como los de Tesla.
La cuestión es que cada vez que uno de estos dispositivos se conecta a la nube realiza un viaje similar al que explicábamos arriba. Por el momento y en la mayoría de los casos eso es suficiente, pero en determinados casos ese viaje es demasiado largo para la rapidez e inmediatez que podríamos obtener si, simplemente, la nube estuviese más cerca.
Dicho de otro modo: tenemos todavía mucho margen de mejora. Las posibilidades que pueden obtenerse si acercamos la nube a donde se generan los datos son simplemente incalculables. Ahí es, precisamente, donde entra en acción el Edge Computing.
Las ventajas del Edge Computing
La mejor definición para entender qué es el Edge Computing es la siguiente: consiste en acercar el poder de procesamiento lo más cerca posible de donde los datos están siendo generados. Es decir, consiste en acercar la nube hasta el usuario, hasta el borde mismo (edge, en inglés) de la red.
Lo que importa cuando hablamos del borde de la red es que acercamos a los usuarios la capacidad de procesar y almacenar datos. Gracias a ello, con el Edge Computing podemos virtualizar las capacidades del servidor y habilitamos que el poder de procesamiento ocurra en esos dispositivos del borde.
Eso permite mover capacidades que antes estaban «lejos», en un servidor en la nube, muchísimo más cerca de los dispositivos. Es un cambio de paradigma que lo cambia todo. Las funciones son similares, pero como el procesamiento sucede mucho más cerca, la velocidad se dispara, la latencia se reduce y las posibilidades se multiplican. Así, se puede disfrutar de lo mejor de dos mundos: la calidad, seguridad y reducida latencia de procesar en nuestro PC, junto con la flexibilidad, disponibilidad, escalabilidad y eficiencia que ofrece la nube.
Edge Computing y las redes de nueva generación (5G y Fibra óptica)
Ahí es donde entra en juego la segunda parte de la ecuación a la hora de entender qué es el Edge Computing: el 5G y la Fibra óptica. Entre sus muchas ventajas, el 5G y la Fibra ofrecen unas reducciones altísimas de latencia. La latencia es el tiempo en el que la información tarda en ir al servidor y volver a ti, la suma del tiempo que se emplea en viaje de ida y de vuelta que explicábamos antes.
Actualmente, el 4G ofrece de media unas latencias de 50 milisegundos. Con el 5G y la Fibra esa cifra puede bajar hasta 1 milisegundo. Dicho de otro modo, no solo acercamos el servidor lo más cerca posible a donde hace falta, al borde, es que además reducimos incluso el tiempo que la información tarda en ir y volver del servidor.
Para entender mejor las implicaciones tan importantes que esto tiene, vamos a plantear tres escenarios diferentes: un coche conectado, un algoritmo de machine learning en una fábrica y un sistema de videojuegos en la nube.
Edge Computing y el coche conectado
El coche conectado del futuro incluirá una serie de cámaras y sensores que capturarán información del entorno en tiempo real. Esa información puede ser empleada de maneras muy diversas. Podrá estar conectado a la red de tráfico de una ciudad inteligente, por ejemplo, para anticiparse a un semáforo en rojo. Podrá asimismo identificar vehículos o situaciones adversas en tiempo real o, incluso, saber en todo momento la posición relativa de los demás coches en torno a él.
Este planteamiento transformará cómo nos desplazamos en coche y mejorará la seguridad de las carreteras, pero el camino hasta él no está exento de escollos. Uno de los más importantes es que toda esa información recogida por las diferentes cámaras y sensores acaba teniendo unas dimensiones considerables. Se calcula que un coche conectado generará unos 300 TB de datos por año (unos 25 GB a la hora). Esa información necesita procesarse, pero mover toda esa cantidad de datos rápidamente entre los servidores y el coche es inasumible, necesitamos que el procesamiento ocurra mucho más cerca de donde los datos están siendo generados, en el borde (edge) de la red.

A modo de ejemplo imaginemos una carretera del futuro por la que circulan 50 coches conectados y que además son completamente autónomos. Eso implica sensores que miden la velocidad de los coches del entorno, cámaras que identifican señales de tráfico u obstáculos en la calzada y toda una serie de datos adicionales. La velocidad a la que la comunicación debe producirse entre ellos y el servidor que controle esa información tiene que ser mínima. Es un escenario donde simplemente no podemos permitirnos que la información viaje hasta un servidor remoto en la nube, se procese, y vuelva.
En lo que eso sucede puede haberse producido un accidente, un cambio brusco en las condiciones de circulación (un animal cruza la vía, por ejemplo) o cualquier otro tipo de imprevisto. Necesitamos que el procesador que opera con la información que producen los sensores de los coches esté lo más cerca posible de los mismos. Con el cloud, esta debería ir hasta la antena (el operador) de ahí viajar por internet hasta el servidor y luego volver, disparando la latencia. Con el Edge Computing, como parte de las capacidades del servidor están en el borde de la red, todo sucede ahí mismo.
Edge Computing y Machine Learning
Gracias a los modelos de aprendizaje automático que ofrece el Machine Learning, muchas fábricas e instalaciones industriales están implementando controles de calidad con Inteligencia y Visión Artificial. Esto, a menudo, consiste en una serie de máquinas y sensores que evalúan cada elemento que se produce en una cadena de montaje, por ejemplo, y determinan si está bien hecho o presenta algún defecto.
Los algoritmos de Machine Learning a menudo funcionan «entrenando» a la inteligencia artificial con miles y miles de imágenes. Siguiendo con nuestro ejemplo, para cada imagen de un producto se le dice al algoritmo si pertenece a un elemento que ha sido fabricado correctamente o no. Mediante la repetición, y bases de datos gigantescas, la IA acaba aprendiendo cuáles son las características de los elementos que no presentan defectos y, si fallan en uno concreto, determina que no ha pasado el control de calidad.
Una vez hemos generado el modelo, lo más habitual es que este se suba a un servidor en la nube al que los diferentes sensores de la cadena de montaje acuden para comprobar la información que recogen. Se repite el esquema que mencionábamos antes: los sensores recogen la información, desde ahí esta tiene que viajar al servidor, procesarse, cotejarse con el modelo de machine learning, obtener una respuesta y volver a la fábrica con el resultado.
El Edge Computing mejora radicalmente ese proceso. En lugar de tener que acudir al servidor en la nube en cada caso, podemos generar una copia (virtualizada o reducida) del modelo de machine learning que se sitúa en el borde de la red. Es decir, prácticamente en el mismo sitio donde se están generando los datos. Así, los sensores no tienen que enviar la información a la nube lejana para cada elemento, sino que cotejan la información directamente con el modelo en el edge y, en caso de que este no concuerde porque el producto es defectuoso, entonces sí envían una petición al servidor. De esta manera, se mejoran las prestaciones, sin necesidad de aumentar la complejidad de los sensores, e incluso se permite simplificar los dispositivos, al poder usar las capacidades de procesamiento desplegadas en el borde de la red para alguna de sus funciones.
Como es evidente, la velocidad de detección de fallos de fabricación se multiplica y se reduce muchísimo el tráfico y el ancho de banda necesario.
Edge Computing y videojuegos
Desde que la primera GameBoy de Nintendo arrasase allá por 1989, uno de los grandes retos de la industria del videojuego ha sido poder ofrecer maneras para jugar en cualquier parte. Se ha llegado lejos con compañías como Xbox, Google, Nvidia o PlayStation que ofrecen soluciones de videojuegos en la nube que permiten ejecutar juegos de última generación en cualquier pantalla.

¿Cómo lo hacen? De nuevo, utilizando el poder de la nube. En lugar de procesar los gráficos del videojuego en el procesador de un PC o de una videoconsola, este se hace en grandes y potentísimos servidores en la nube que simplemente envían la imagen resultante por streaming hasta el dispositivo del usuario. Cada vez que este aprieta un botón (por ejemplo, para que Super Mario salte), la información de esa pulsación viaja hasta el servidor, se procesa, y vuelve. Hay un flujo continuo de imagen, como si fuese un streaming de vídeo como Netflix, hasta el usuario. A cambio, lo único que necesitas para jugar es una pantalla.
Para que el jugador perciba que el proceso desde que aprieta el botón de saltar hasta que Super Mario salta en su pantalla sea instantáneo, los tiempos de latencia tienen que ser bajísimos. Si no, percibiría un incómodo retraso (también conocido como lag) que arruinaría toda la experiencia.
Gracias al Edge Computing podemos acercar el poder de la nube (los servidores que procesan los gráficos de los videojuegos) hasta el borde mismo de la red, reduciendo enormemente el retardo (lag) que se produce cada vez que el usuario aprieta el botón y ofreciendo una experiencia prácticamente idéntica a la que se produciría si la consola estuviese al lado.
Edge Computing: por qué ahora y por qué va a cambiar el futuro de la conectividad
Aunque hemos explicado todo el proceso de manera muy simplificada, la realidad es que el Edge Computing requiere de una serie de tecnologías y protocolos de última generación para que funcione correctamente. Es posible que en algún momento te hayas preguntado por qué no se había hecho todo esto hasta ahora, es decir, por qué la nube no se diseñó desde un principio para estar lo más cerca posible de donde se generan los datos.
La respuesta es que era imposible, para que el Edge Computing funcione correctamente necesitamos, entre otras cosas, una conectividad de última generación sustentada en fibra óptica y en 5G. Cuanto mejor sea el despliegue de red, mejor será el Edge Computing. Sin la velocidad ni latencia tan baja que ofrece la combinación de ambos, todos los esfuerzos en acercar el poder de la nube al borde a donde se procesan los datos, quedarían en vano. La red simplemente no estaría preparada.
Gracias a sus extensos despliegues de fibra (en países como España hay más cobertura de fibra que en Alemania, Reino Unido, Francia e Italia juntas), compañías como Telefónica están especialmente preparadas para desplegar casos de uso sobre el Edge Computing.
El Edge Computing cambiará el mundo en los próximos años. Hará que los servicios en la nube de los que disfrutamos suban un nivel. Solo el tiempo y el potencial infinito de internet saben qué nuevas tecnologías y aplicaciones maravillosas nos aguardan tras él.
Fuente: empresas.blogthinkbig.com
Comments
- Las mejores plantillas de currículum para Google Docs abril 24, 2024Hay muchos recursos en línea para ayudarlo a crear un currículum estelar The post Las mejores plantillas de currículum para Google Docs appeared first on Digital Trends Español.
- Vas a odiar el último cambio en Windows 11 abril 24, 2024Parece que Microsoft está cambiando la forma en que funciona la sección Recomendado en general The post Vas a odiar el último cambio en Windows 11 appeared first on Digital Trends Español.
- Impresionante máquina expendedora de CPU de Intel en Japón abril 24, 2024¿Qué tipos de CPU son las que tiene esta máquina? The post Impresionante máquina expendedora de CPU de Intel en Japón appeared first on Digital Trends Español.
- Incluso el nuevo Snapdragon X Plus de gama media supera al M3 de Apple abril 24, 2024Qualcomm ha construido este chip teniendo en cuenta la eficiencia y la velocidad The post Incluso el nuevo Snapdragon X Plus de gama media supera al M3 de Apple appeared first on Digital Trends Español.
- 6 consejos para usar la computadora si sufres de migraña abril 24, 2024¿Sufres de migraña y debes usar la computadora? Haz tus sesiones de trabajo más llevaderas con estos consejos. The post 6 consejos para usar la computadora si sufres de migraña appeared first on Digital Trends Español.
- Cómo reinstalar Windows 11 sin perder archivos ni programas abril 23, 2024Te guiamos paso a paso sobre cómo reinstalar Windows 11 sin perder archivos ni programas. The post Cómo reinstalar Windows 11 sin perder archivos ni programas appeared first on Digital Trends Español.